Basic Git Knowledge
Doing the job of a developer, we work with Git on daily basic and sometime we just feel fine and go on with some basic git flow. Have you ran into a git problem and hesitate to make any further steps to fix it? I think Git problem is something we cannot avoid, so why don’t we spend a little time to dive deeply into it? Let’s get started. Before we can imagine on different scenarios, let’s take a look at some basic stuff.
I. Git Basic
I would recommend you to read this book to get a good start on Git.
Basically, Git repository is a directory which is using Git to keep track of the changes happening in this directory.
To turn a normal directory into a Git repository, first you need to install git on your computer and then go into that directory, execute git init.
1. Git File
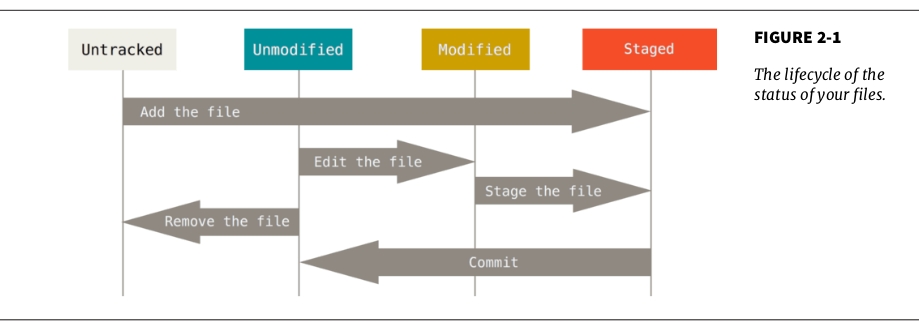
Every files resided in a Git repo has a status which is one of these:
- untracked (the file has been included since last snapshot)
- unmodified (the file stay the same as last snapshot)
- modified (the file has changed compare to last snapshot)
- staged (that change has been staged to be committed, commit make the changes permanent)
(snapshot = commit)
2. Git Directory
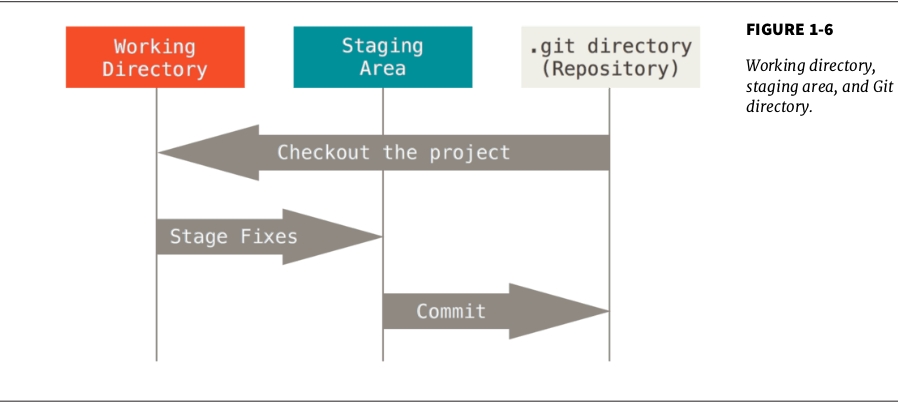
With the status of file mentioned above, Git has 3 different directores for files to reside. If a file is untracked, it did’t belong to Git repository (it just belongs to normal directory), so Git don’t have room for these type of files.
- For modified files, they resides in Working Directory
- For staged files, they reside in Staging Area (sometimes called Index)
- After being committed, these staged files will reside in .Git repository and become permanent (unmodified) in the Git repo, start a new life cycle.
3. Git Commit
Of course, commit is something only when it’s in a Git directory.
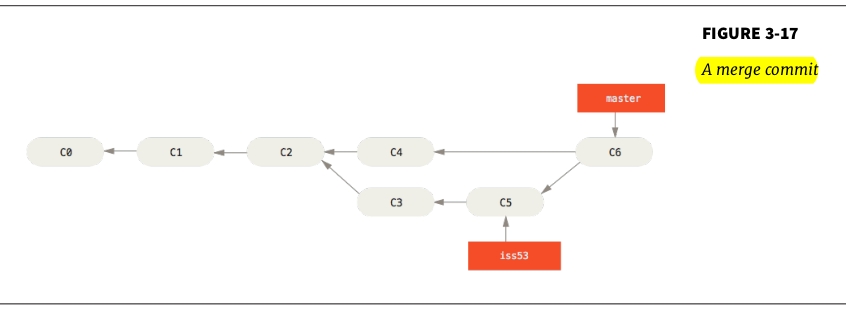
All commits in a Git Repo will form a DAG (Directed Acyclic Graph) in which each node is a commit.
Every normal commit has 1 parent except for merge commit which has 2 parent.
Example:
II. Usage
After having a good git basic, let’s dive into pratical use. I just take note in some of most confusing usage.
1. Reset
First and foremost, Reset will lose your commit forever.
Recall that commit is a node of change in your whole DAG.
There are 3 options when using reset: –soft, –mixed, –hard.
Let’s say our Git repo has this DAG:
C0 <– C1 <– C2 <– C3
Our HEAD is pointing to C3, if we operates git reset C1, out DAG will be regardless of which option we have chosen.
C0 <– C1
So the question: Did we lose the changes in node C2 and C3?
Yeah, This question is where options come into the picture. It depends:
- If we chose –soft, these changes (C2&C3) will still reside in
Staging Area (Index) - If we chose –mixed, these changes (C2&C3) will still reside in
Working Directory - If we chose –hard, these changes (C2&C3) will be gone forever
One of the common applications of git reset beside actually reset, we can use it to squash last n commits into 1 commit. Just by performing 2 operations.
1$ git reset --soft HEAD~n
2$ git commit -m 'squash last n commits'
2. Merge
I think this is the most powerful and common git usage, don’t we always use git merge in working? Let’s say we are working on current branch (master) and we want to merge the merged branch (feature) to out master. Git firstly find the LCA (Lowest Common Ancestor) of 2 branch and perform:
- Fast-forward: If our HEAD (master) is LCA , Git just simply move the HEAD pointer to last commit of feature branch.
DAG: C0 <-- C1 (HEAD: master)
\
C2 <-- C3 (feature)
- 3-way merge: Git will create an extra commit (merge-commit) which magically contains all changes from feature branch and put this commit ahead of 2 branch, move HEAD (master) to here, this commit is special because it has 2 parent
Notable Scenarios
This is what happens after you merge an unwanted branch to current branch, it might because you’ve resolved incorrectly.
- If you want your current branch to back to the before-merge snapshot,
Git reset to first parentwill help you. Notice thatGit resetis a very dangerous operation, espcially if you already published your commit since other people may reply on that commit. - If you want to reset to the middle of feature branch, you might end up losing all commits after LCA on master branch. Honestly, everything that you already committed won’t be lost, I mean here is you don’t have any pointer to keep track of these commit.
Example
C0 <-- C1 <-- C3 <--C5 (master)
\ /
C2 <-- C4 (feature)
If you reset to C2 from master, there is no pointer to keep track of commit on old master branch, so you can’t recall C3 and C5 commit anymore (from a naive perspective)
I’s worth noting here that you can also recall C3, C5 by reading git reflog (this is the log record the HEAD pointer movement), using git reset HEAD@{n}, this way you move the HEAD point back to C5 and start tracking master branch again.
this answer might help, scroll down to ashish’s answer.
–> And just here, you can also realize that branch is nothing rather than a pointer in DAG, so create as much as you can, no worry.
- Re-doing a merged commit
If you can’t use reset like mentioned above, you can do this trick to recreate all your changes from feature branch and merge it again. In case you already resolved correctly while merging feature branch, you can do like this, 2nd answer. But in case you resolved incorrectly, there is noway git can know what is correct, so the only to mitigate this issue is, this is my idea.
–> From your feature branch, squash all commits into 1 commit (using git reset && commit again), so now your feature branch has a totally different history (of course different commit hash) and when you merge again, git won’t recognize anything.
3. Git rebase
rebase is another way to integrate your changes to master branch, but it will change the history, so Rebase should only use on your local work. This video timestamp 37:30
Why did i say It changes the history? More correctly, It only changes the order of commits, not the commit metadata (date/author) itself.
This post is the result of a lazy work of a depressed developer. So feel free to critisize.